Week 2
Updated 2022-01-18
Original slides/talk from Mieszko Lis.
Calling Convention
We’re familiar to definition and calling functions in higher level languages like Java and C and it just works:
int secret_stuff(char *arg, int z) {
ans = more_secret_stuff(x, y, z, arg);
}
But on a register level, how does function call actually work? Where does the arguments x go?
The caller and callee must agree on a few things:
- Passing arguments – how do we pass arguments and inputs from one frunction to another? Which registers to use
- Reciving result – how does the caller receive the output of the function
- Passing return addresses – when we call a function, we’re essentially handing control over to the function we’re calling. But how do we make sure program comes back to us after the function is done?
- Storing local variables – when we call a function, we must not let it override local variables in our own scope. How do we ensure this?
Note that this is not language-specific – since it’s possible for a Java function to call binaries in a different language.
All these agreements are esentailly add up to calling convention
Call Frame
Call frame (or activation record) is a record for functions’ local storage. It’s allocated when a function is called and removed when a function returns. The call frame is often arranged as a call stack.
In a call frame, there is a frame pointer that points to the beginning of the frame. This pointer is set when the function is invoked.
There is also a stack pointer that points to the top of the stack. The stack pointer may move since we may put things on the stack inside the function.
Example:
Suppose we’re in some function and we call a function foo(), then we allocate the call frame for function foo(). Then the frame pointer will point at the beginning and the stack pointer points to the “top” of stack:
If inside foo() we call another function bar(), then we allocate call frame for bar() and then we move the stack pointer.
When bar() returns, we remove the frame and return to foo().
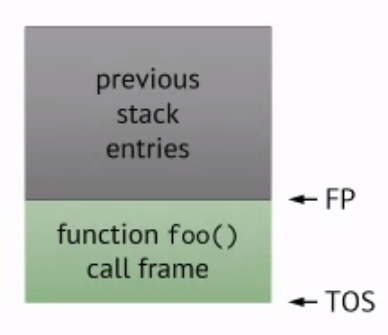
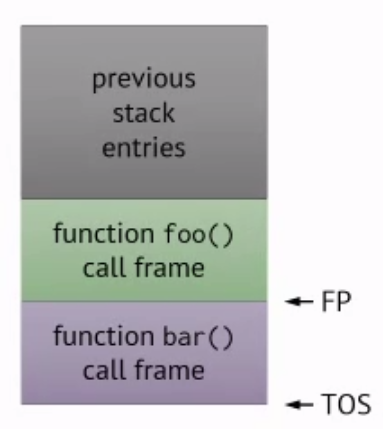
Arguments and Return
Now knowing the frame and the stack, we can look at how argument and return values are passed around.
How do we go back?
Return addresses is the where the program should go after function finishes/returns. In x86 systems, return addresses are located on stack and in ARM the address is stored in register x30.
Return values are put in rax, and x0 and frame pointers are stored in registers rap (x86) and x29 (ARM).
How do we pass arguments
In x86, we put the arguments in registers rdi, rsi, rdx, etc. ARM does it the same except registers are not named: x0, x1, x2, etc.
If there are more than 7 (x86) or 8 (ARM) arguments, then you can push it on the stack. Values can then be popped from the stack once we enter into the function.
Special Instructions
There are special instructions such as call, ret (x86) and bl, ret that help facilitate function calls. For example, calling ret in ARM is the same as br x30 (branch to address stored in return address register).
Calling A Function Inside A Function
What happens if I’m already inside a function and I call another function? Wouldn’t the inner function overwrite critical registers (such as the return address register x30?).
Then the question becomes: should registers values to be preserved across calls? And there are two options:
- Caller saves the registers before calling a function.
- Pros: Callee don’t have to do extra work.
- Cons: if we don’t know which registers callee is using, then we have to save everything.
- Callee saves the register before executing its body.
- Pros: callers don’t have to do extra work
- Cons: all registers are saved regardless if caller uses it or not.
In practice, typically some registers are saved by callee and anything else must be saved by the caller.
Example: consider this following function that follows the callee-saved convenction in x86 assembly:
myfunction: push rbp mov rbp, rsp sub rsp, 48 ; body of function ... mov rsp, rbp pop rbp retUpon entering the function, we push the base-pointer/frame pointer (
rbp), then we put the return address on the stack.We also move the stack pointer by 48 bytes (or how ever much stack space we need inside this function).
Then we can execute the body of the function.
Once we’re done, we just need to pop the stack by putting the frame pointer (
rbp) onto the stack pointer and pop it.
Often in compiler generated code, the frame-pointer is often omitted for optimization reasons (saves one register). Since the compiler can keep track of how much offset to add/remove from the stack.
Despite the optimization, frame pointer is necessary if we don’t know exactly how much we’re putting on the stack in a function (e.g. dynamically-szied memory using alloc()) – since compilers cannot know the stack offset during compile-time.
Interrupts
When a user presses a key for example, it goes into an interrupt handler/service routine. In this case, should the interrupt handler use your memory?
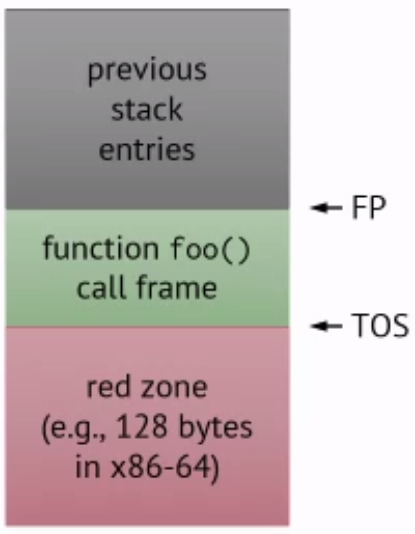
In practice, there is a red zome which is a fixed-size space below top-of-stack (TOS). This area is guaranteed to not be touched by interrupts.
This is nice because we don’t need to update the stack pointer whenever interrupt happens.
Other Considerations
- Address alignment rules - x86 requires stack ot be aligned at 16-byte boundaries
- Exceptions - if there is a control flow that isn’t standard function calling, there needs to be stack unwinding to communicate this information for non-local control flow like exceptions (???)
- Name mangling - In C++ and Java there can be the functions of the same name in different classes or namespaces/packages. During runtime, how can we figure out which function to call?
TL;DR: Calling conventions enables different part of the code to just work.
Example
We want to write some code to print some strings to the screen. We write and utilize a function print which takes a pointer to ASCII string and prints it to stdout.
-
The arguments are:
rdi,rsi,rdx,rcx,r8,r9, stack and return value goes inrax. -
Callee-saved registers are:
rbx,rbp,r12-r15
So let’s start with:
section .text
global _start
_start:
mov rdi, hi
call print
mov rdi, bye
call print
mov rax, 60
xor rdi, rdi
syscall
hi db "hello, world!", 10, 0
bye db "goodbye, cruel world...", 10, 0
- We first move
hiwhich contains the ASCII text “hello, world!” intordias the first-argument into the function. Note that - Then we call print function, which will get the ASCII text via register
rdi. - After printing both strings, we perform syscall to actually output it to the screen/stdout (see Week 1).
The print function is:
print:
push rdi
call len
pop rdi
mov rdx, rax
mov rsi, rdi
mov rax, 1
mov rdi, 1
syscall
ret
- We want to call a function
lento figure out how long the string is to print. - But before that we need to push
rdito the stack because it’s not guranteed to be preserved and we might use it later. We could alternatively move it to a register that is saved or not overwritten (such asrbx) - We move the return value from calling
len(rax) tordxas arguments to the syscall for output
Here is the len function:
len:
push rbx
xor rbx, rbx
len_loop:
cmp byte [rdi], 0
je len_end
inc rbx
inc rdi
jmp len_loop
len_end:
mov rax, rbx
pop rbx
ret
- The first thing we do is to push
rbx. We do this becauserbxis callee-saved (as per calling convention mentioned). So if we want to use this register, we must push it to the stack and pop it once we’re done. - The body of the function basically computes number of characters (loop until it sees a null character (0)), and returns by putting the count into
rax.
Drawbacks
- Stacks are sequential / one-directional
- What if we have two functions that grow the stack in two directions?
- Stack space is deallocated on return
- What about first-class functions or closures?
Ad-hoc Polymorphism
Assembly language can’t distinguish between super:foo() or sub::foo(), so how does this work? Consider these instructions: they go to some address in register rax. These are indirect jumps (e.g. functions).
jmp [rax]call [rax]
Then recall dynamic dispatch: consider the code example we’ve seen from week 1. The dispatch for deciding which function to use is only decided during runtime because it’s not possible to know at compile-time.
#include <iostream>
struct Super {
void foo() { std::cout << "Super::foo()\n"; }
virtual void bar() { std::cout << "Super::bar()\n"; }
}
struct Sub : Super {
void foo() { std::cout << "Sub::foo()\n"; }
void bar() { std::cout << "Sub::bar()\n"; }
}
int main() {
Super *obj = new Sub();
obj->foo(); ❶
obj->bar(); ❷
}
At ❶, the foo() function is known statically, whereas at ❷, the bar() function is only known at runtime and cannot be inlined beforehand. We can make the following observations:
- There are two (or even more) versions of
bar()function - Somehow we need to rename the
bar()functions generate assembly code labels so they can be distinguished.
To achive what we need to do, we need to consider:
- Name Mangling – “maybe we can rename them to
foo0andfoo1?” - but how would you figure the sequence? - Storange – other fields (variables) inside a class
- Non-virtual method calls
- Virtual method calls – how do we actually call the functions? (Hint: indirect jumps and calls)
- Inheritance – how should we handle derived classes?
Name Mangling
Same field/function names can show up many times in different namespaces and classes. To mangle the name is to make them unique.
A naive way of name-mangling is to label them with numbers: (e.g. foo1, foo2, etc). But this is actually not that good because you don’t know how to sequence them such that each of them is unique.
In C++, for example anything starting with _Z is reserved (user can’t write a function of the same name): and it’s reserved as a prefix for renaming:
| Before | After mangling |
|---|---|
int add(int, int) |
_Z3addii |
double add(double, double) |
_Z3addd |
char *cat(char *, const char *) |
_Z3catPcPKc |
void noarg() |
_Z5noargv |
int Cls::method(int x, int y) |
_ZN3Cls4methodEii |
This does a pretty good job ensuring that functions have a different name. But notice: how and why are return type encoded in the mangled function name?
This is because in C/C++ is that a function with same argument cannot have a different return type.
Example: consider the follwing code:
#include ‹iostream> struct animal { int age; const char *name; animal(const char *, int); void say_name(); }; animal::animal (const char *n, int a) { name n; age = a; } void animal: :say_name() { puts(name); } int main() { animal a("whisky", 10); a.say_name(); }The first thing we need to consider is data storage. How storage do we need to store one instance of this class.
To compute it we need to store
age(4-byte integer) with another 4-byte padding for alignment andname(pointer to some character / so it’s 8 bytes on a 64-bit machine).Notice: we don’t need to store anything for the functions as they are all non-virtual and doesn’t need dynamic dispatching. So name-mangling shoould be straight forward.
Let’s rename the
say_namemethod:_ZN6animal8say_nameEv() { puts(name); }Problem: what is
name? How do we find it?
Let’s try again, we need to pass an argument that can be used to identify where the class’s data is:
_ZN6animal8say_nameEP(animal *self) { puts(self->name); }So now everytime we we refer to
nameit’s actually implicitly refering to itself. We we write code in C++ or Java and we usethis.for example, such argument is just hidden from us.Let’s also mangle the constructor now:
_ZN6animalC2EPKcí(animal *self, const char *n, int a) { puts(self-›name); } _ZN6animalCIEPKci equ_ZN6animalC2EPKci
Now we can represent C++ in lower level C once we’ve done all of this. Now let’s go a step further and look at the assembly:
; Constructor _ZN6animalC2EPKci: mov qword [rdi+8], rsi mov dword [rdi], edx ret
- Recall
rdiis the first argument andrsiis the second argument.- The first instruction takes the second arugmnet puts it into the first argument (which is the self-referencing pointer) + offset of 8-bytes which gives us the second field.
- Same with second argument which is the age
; say name _ZN6animla8say_nameEv: mov rdi, qword [rdi+8] jmp puts
- We put the name field from
rdi(self) intordi(first argument) then call the function puts.main: sub rsp, mov edx, 10 mov rsi, WHISKY mov rdi, rsp call _ZN6animalC1EPKci call _ZN6animal8say_nameEv xor eax, eax ; zeroes the registers for exit code add rsp, 24 ret WHISKY db "whisky", 0
- Note:
callputs something on the stack and jumps to an address, return pops something from the stack and jumps to an address. So it’s just more convenient to usecallandretsometimes.
What happens when we derive class?
Suppose we have this:
struct dog animal { dog (const char *, int); void say_name(); ); dog::dog(const char *n, int a) : animal (n, a) { } void dog: : say_name() { animal::say_name(); puts ("WOOF!"); } int main() { dog d("whisky", 10); animal *a = &d; a->say_name(); }and it’s assembly code:
_ZN6animalC2EPKci: mov quord [rdi+8], rsi mov duord [rdi], edx ret _ZN6animal8say_nameEv: mov rdi, word [rdi+8] jmp puts _ZN3dogC2EPKci: jmp _ZN6animalC2EPKci _ZN3dog8say_nameEv: sub rsp, 8 call _ZN6animal8say_nameEv mov rdi, WOOF add rsp, 8 jmp puts main: sub rsp, 24 mov edx, 10 mov rsi, WHISKY mov rdi, rsp call _ZN3dogC1EPKci call _ZN6animal8say_nameEv ❶ xor eax, eax add rsp, 24 ret
- There is a problem: the call to
say_name❶ actually goes to the animal super class and not the method in the derived class – so more work needs to be done.- i.e. name mangling is not good enough for dynamic dispatch.
Dynamic Dispatching
One way to do is to include a virtual table pointer for virtual functions as part of our data storange:
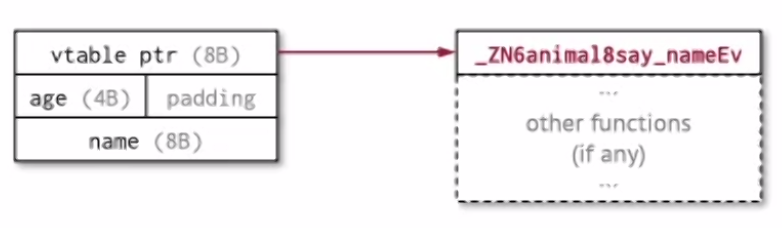
This is nice because it’s carried with the object.
Note: When compiled, there’s actually two more fields:
- Base offset
- Runtime type info (used by the debugger)

Question: do we need constructors in the virtual table?
No. because constructors are not overridable.
Example: consider previous C++ example except we used virtual keyword for dynamic dispatching (❶):
#include ‹iostream> struct animal { int age; const char *name; animal(const char *, int); virtual void say_name(); ❶ }; animal:: animal (const char *n, int a) { name n; age = a; } void animal: :say_name() { puts(name); } int main() { animal a("whisky", 10); a.say_name(); delete a; }Now the
say_namemethod is:_ZN6animal8say_nameEv: mov rdi, qword ptr [rdi+16] jmp putsIt’s the same as before except we also need to increase the offset to skip the vtable.
Constructor:
_ZN6animalC2EPKci: mov qword [rdi], _ZTV6animal+16 mov qword [rdi+16], rsi mov qword [rdi+8], edx ret _ZN6animalC1EPKci eq _ZN6animalC2EPKciNow in
main:main: sub rsp, 40 mov ecx, edi mov edx, 10 mov esi, WHISKY mov rax, rsp mov rdi, rax call _ZN6animalC1EPKci mov rdi, rsp mov rax, qword [rdi] ; puts vtable in rax call quord [rax] ; calls the address in the vtable (the function) xor eax, eax add rsp, 40 ret
- Now we see that instead of calling the name-mangled function from the super class
animal, we instead load the vtable torax. Thenraxholds the address to our vtable – which holds our virtual functions.- Then we can just
callthe function address located in the vtable.
Inheritance
Now knowing we have a vtable, derived class simply just changes the content of the vtable.
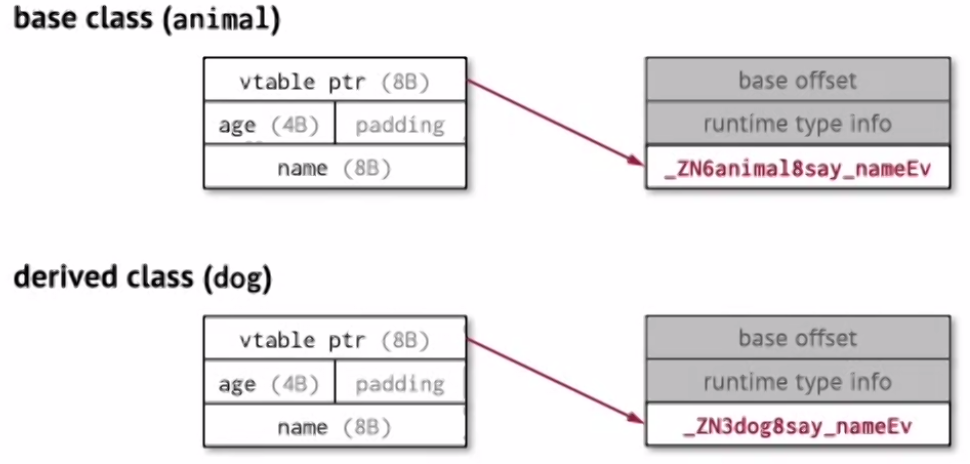
If there are multiple inheritances (i.e. a derived class dog that is both an animal but also derives from a swimmer class).
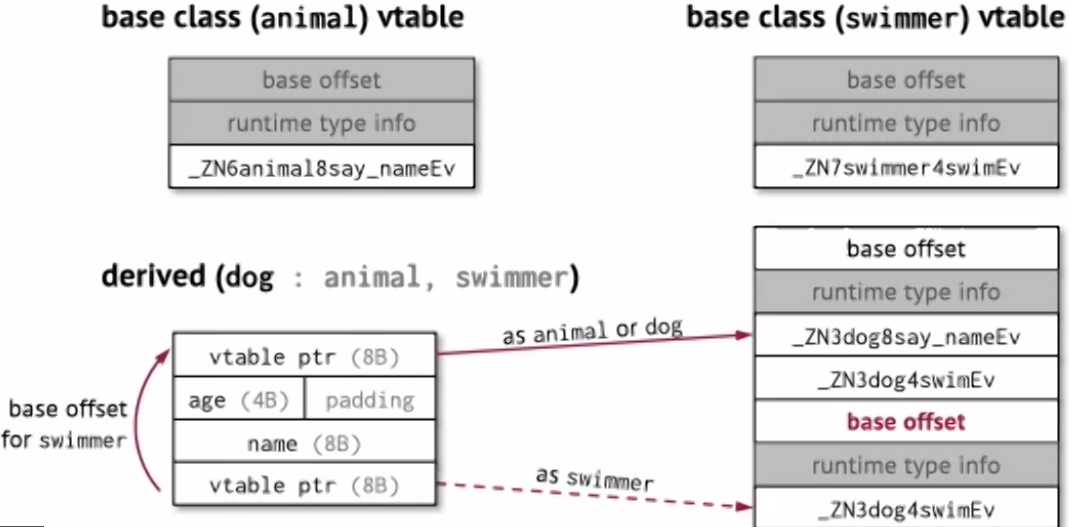
Then we simply merge the virtual functions as part of dog’s’ vtable. If it happens that the dog object is casted to a swimmer object, then we can have a second vtable pointer that points to a vtable as if it’s of type swimmer.
Traits / Interface
One thing implication of vtable is that it enables trait – where a derived class can be extended to perform a different behaviour.
For example, given a Dog class, we can extend its behaviour without modifying the original class definition:
struct Dog { age: 132, name: String }
trait Named ( fn say_name(&self); }
impl Named for Dog { fn say_name(&self) ( println!("{}", self. name )} }
trait Swimmer { fn swim(&self); }
impl Swimmer for Dog { fn swim(&self) { println! ("swimming") } }
Closures
IN a real computer, there are thigns happening all the time such as events and interrupts. Typically, there are functions for handling this event, and those are closures.
Consider this snippet of code in Go
func addTo(x int) func(int) int {
return func(y int) int {
return x + y
}
}
func main() {
add2 := addTo(2)
fmt.Println(add2(7))
}
The function addTo returns a function/closure. So in this case, we call the function addTo to create a new function called add2, then we can call add2 function to produce 9 (since 7 is the parameter).
Same thing in Haskell:
let add2 = (2 +)
in print (add 2 7)
This might be useful because it can be used for higher-order functions like map (applying the same function to a list of objects), event listeners, data hiding (e.g. in jQuery). We can use closures to do lazy-evaluation (we call the function and assign to the variable, but the runtime system don’t evaluate it until the variable is actually needed).
Abstractions on Indirect Jumps Summary
So far we saw function calls, function returns and its calling conventions. We also learned ad-hoc polymorphism to enable object-oriented programming and inherietances, interfaces, and traits. Lastly, we saw how this enables closures.